依照維基百科的說明,樞紐分析表是一種用來呈現資料性質總結(如計數,加總,平均或其他 Aggregation )的工具。
而一個樞紐表包含三個部份:
- 垂直欄位:這個欄位中,包含相異的品項。作為樞紐表的 Y 軸
- 水平欄位:和垂直欄位一樣,也包含相異的品項,但內容會挑跟垂直欄位不相同的項目來用。作為樞紐表的 X 軸
- X/Y 張開的表格之間:為要呈現的總結資訊。也就是,固定 (X, Y) 條件下,所得的 Aggregation 資訊(例如,固定 (X,Y) 條件後的資料筆數,或是固定 (X, Y) 條件下,其他欄位資料的平均值)
- (選擇性)對 X 軸 / Y 軸作小計
對應到關聯式表格的結構。樞紐表把兩欄用「品項」當成資料內容的關聯式表格欄位,挑出相異品項的清單,當作樞紐表的 X/Y 欄位陳列的「標籤」(例如,可以用 enum 型態來列舉資料內容的欄位,或是紀錄每日的日期/月份的欄位,都可以當成樞紐表 X/Y 軸的標籤);而中間的內容,就是對照 (X, Y) 值當成條件的 Aggregation 結果。
要從關聯式表格產生樞紐分析表,便要組織 SQL 查詢,呈現結果,再使用樞紐表組織工具處理
- 準備作為 X 軸的欄位資料
- 準備作為 Y 軸的欄位資料
- 準備用來作總結的資料
以上的關係搞清楚之後,樞紐表能不能用 PostgreSQL 資料庫的 SQL 語法完成?
在 PostgreSQL 裡面提供了一個叫做 tablefun 的內建模組(PGSQL 8.3 之後引入),裡面有一個作樞紐分析表的工具 crosstab(),可以達成用設計過的 SQL 指令產生樞紐表的功能。
而在 9.6 版的客戶端指令界面 psql 下,有更容易使用的工具 \crosstabview,它針對前一次執行的 SELECT SQL 指令(需要是有設計過,呈現樞紐表結果的 SQL 指令,且不和 tablefun 模組的 crosstab() 函數混用!)結果以樞紐表的方式呈現。
- tablefun 模組的 crosstab(sql_text, sql_text) 函數,會吃兩個參數:第一個參數放的是組織過的 SELECT SQL 指令,第二個參數則是自行指定 X 軸品項的 SELECT SQL 指令(欄位裡面可能不見得每一品項都已經有資料,如月份資料還沒有存滿一年,這種狀況就能夠手動指定)。而最後回傳結果要當作 Set-Returning Record 來處理,把輸出的樞紐表當成普通表,指定各欄位(樞紐表 X 軸)的「名稱」
- psql 的 \crosstabview 可以接四個參數,前兩個參數是準備用來作樞紐表的水平/垂直欄位,第三個參數是樞紐的值,而第四個是選用的,用來指定水平欄位值排序的欄位。功能比 crosstab() 函數陽春一些,不果相對來說也比較簡單一點。
以下為一個 PGSQL 裡的關聯式表格與它的資料作為操作示範的範例(參考來源:EDB 範本資料)
edb=# select deptno, job, sal
from emp order by deptno;
deptno | job | sal
--------+-----------+---------
10 | CLERK | 2031.25
10 | MANAGER | 3828.13
10 | PRESIDENT | 7812.50
20 | ANALYST | 4687.50
20 | MANAGER | 4648.44
20 | CLERK | 1250.00
20 | CLERK | 1718.75
20 | ANALYST | 4687.50
30 | SALESMAN | 1953.13
30 | SALESMAN | 2343.75
30 | SALESMAN | 2500.00
30 | MANAGER | 4453.13
30 | SALESMAN | 1953.13
30 | CLERK | 1484.38
(14 rows)
把資料用格子呈現的話如下(弄到 Libreoffice Calc 裡面作後續示範)
deptno
|
job
|
sal
|
10
|
CLERK
|
2031.25
|
10
|
MANAGER
|
3828.13
|
10
|
PRESIDENT
|
7812.5
|
20
|
ANALYST
|
4687.5
|
20
|
MANAGER
|
4648.44
|
20
|
CLERK
|
1250
|
20
|
CLERK
|
1718.75
|
20
|
ANALYST
|
4687.5
|
30
|
SALESMAN
|
1953.13
|
30
|
SALESMAN
|
2343.75
|
30
|
SALESMAN
|
2500
|
30
|
MANAGER
|
4453.13
|
30
|
SALESMAN
|
1953.13
|
30
|
CLERK
|
1484.38
|
對上述表格建立樞紐表,通常有兩種:
(一) 總結樞紐表:此處範例示範的問題為,在部門編號 deptno 為 '10' 時,職稱 job 為 'Clerk' 的人有多少個?
用 Libreoffice Calc 的話,可以把上述 SQL 用 csv 匯出,然後用 Calc 開啟,就能夠拉樞紐表
使用步驟
1. 先把資料範圍選起來
2. 點 「資料 → 樞紐分析表 → 建立」

3. 把可用欄位 deptno 拖拉到「列的欄位」,job 拖拉到「欄的欄位」,再拉一次 job 到「資料欄位」,這時呈現「總和 - job」

4. 在「資料欄位」中「總和 - job」點兩下,換成計數,此時便會呈現「數計數 - job」
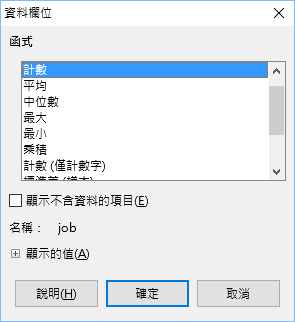 |  |
5. 得到結果!
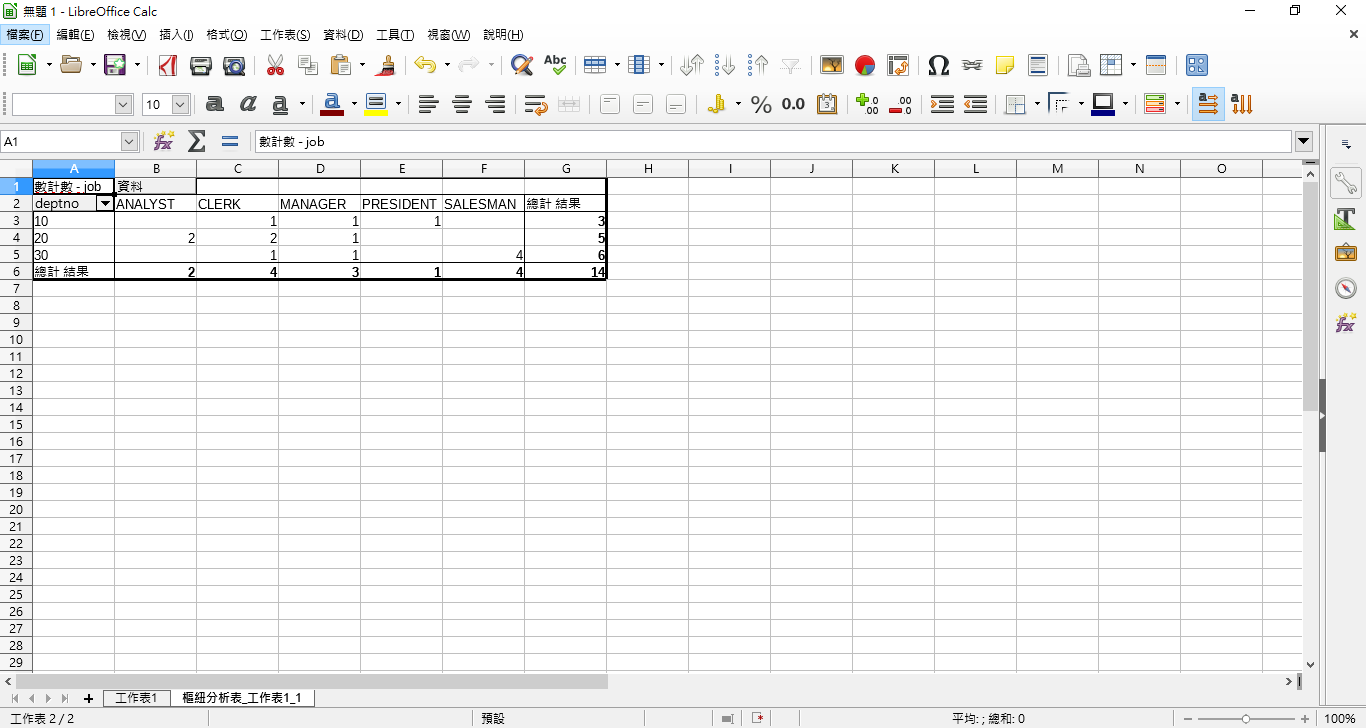
以上是一般樞紐表操作步驟和結果。而在 PGSQL 的話,首先,先組織出所需資料的 SQL 指令
edb=# select deptno, job,
count(job) AS "# of workers "
from emp group by deptno, job
order by deptno,job;
deptno | job | # of workers
--------+-----------+---------------
10 | CLERK | 1
10 | MANAGER | 1
10 | PRESIDENT | 1
20 | ANALYST | 2
20 | CLERK | 2
20 | MANAGER | 1
30 | CLERK | 1
30 | MANAGER | 1
30 | SALESMAN | 4
(9 rows)
使用 tablefun 模組的 crosstab() 函數作樞紐表,比較困擾的是,必須事先得知 X 軸會有哪些品項才行
edb=# SELECT * FROM crosstab( $$select deptno, job, count(job) AS "# of workers" from emp group by deptno, job order by deptno,job$$ , $$select distinct job from emp order by job$$) AS ("dept No." int, "ANALYST" text, "CLERK" text, "MANAGER" text, "PRESIDENT" text, "SALESMAN" text); dept No. | ANALYST | CLERK | MANAGER | PRESIDENT | SALESMAN ----------+---------+-------+---------+-----------+---------- 10 | | 1 | 1 | 1 | 20 | 2 | 2 | 1 | | 30 | | 1 | 1 | | 4 (3 rows)
上面要注意的是,兩句 SQL 指令是類似 Dynamic SQL 一樣,當成字串,放到樞紐表函數內的。
使用 \crosstabview 作樞紐表,只要在 SQL 指令後面不加分號,直接接上 Meta-command 就好。先來試一下沒有指定 X 軸排序的狀況
edb=# select deptno, job, count(job) AS "# of workers " from emp group by deptno, job order by deptno,job \crosstabview deptno job deptno | CLERK | MANAGER | PRESIDENT | ANALYST | SALESMAN --------+-------+---------+-----------+---------+---------- 10 | 1 | 1 | 1 | | 20 | 2 | 1 | | 2 | 30 | 1 | 1 | | | 4 (3 rows)
如果要指定 X 軸品項的排序,就得要使用 Window Function row_number() 多產生一個欄位才行
edb=# select deptno, job, count(job) AS "# of workers ", row_number() over(order by job) AS ord from emp group by deptno, job order by deptno,job \crosstabview deptno job "# of workers " ord deptno | ANALYST | CLERK | MANAGER | PRESIDENT | SALESMAN --------+---------+-------+---------+-----------+---------- 10 | | 1 | 1 | 1 | 20 | 2 | 2 | 1 | | 30 | | 1 | 1 | | 4 (3 rows)
(二) 對 X/Y 軸標籤欄位之外的其他資料的作統計:在這裡用問題範例是,各個部門內同樣職銜的人的薪資的平均
先放一個 Libreoffice 下樞紐表的結果,步驟同上,只是現在換成拉 sal 到「資料欄位」,並選擇「平均 - sal」

呈現結果

接著一樣,要在 PGSQL 裡面處理的話,先確定查詢的 SELECT 指令
edb=# select deptno, job,
avg(sal) AS "Average Salary"
from emp group by deptno, job
order by deptno,job;
deptno | job | Average Salary
--------+-----------+-----------------------
10 | CLERK | 2031.2500000000000000
10 | MANAGER | 3828.1300000000000000
10 | PRESIDENT | 7812.5000000000000000
20 | ANALYST | 4687.5000000000000000
20 | CLERK | 1484.3750000000000000
20 | MANAGER | 4648.4400000000000000
30 | CLERK | 1484.3800000000000000
30 | MANAGER | 4453.1300000000000000
30 | SALESMAN | 2187.5025000000000000
(9 rows)
使用 tablefun 模組的 crosstab() 函數作樞紐表,在這裡我要把第一格重新命名成 "Average Salary",這是不影響的
edb=# SELECT * FROM crosstab( $$select deptno, job, avg(sal) AS "Average Salary" from emp group by deptno, job order by deptno,job$$ , $$select distinct job from emp order by job$$) AS ("Average Salary" int, "ANALYST" text, "CLERK" text, "MANAGER" text, "PRESIDENT" text, "SALESMAN" text); Average Salary | ANALYST | CLERK | MANAGER | PRESIDENT | SALESMAN ----------------+-----------------------+-----------------------+-----------------------+-----------------------+----------------------- 10 | | 2031.2500000000000000 | 3828.1300000000000000 | 7812.5000000000000000 | 20 | 4687.5000000000000000 | 1484.3750000000000000 | 4648.4400000000000000 | | 30 | | 1484.3800000000000000 | 4453.1300000000000000 | | 2187.5025000000000000 (3 rows)
用 \crosstabview,除了把 Meta-Command 緊接著 SQL 之外,也可以在執行完 SQ㏒接著執行 Meta-Command。此外這個 Meta-Command 不能像 crosstab() 直接重新命名第一格
edb=# select deptno, job, avg(sal) AS "Average Salary", row_number() over(order by job) AS ord from emp group by deptno, job order by deptno,job; deptno | job | Average Salary | ord --------+-----------+-----------------------+----- 10 | CLERK | 2031.2500000000000000 | 3 10 | MANAGER | 3828.1300000000000000 | 7 10 | PRESIDENT | 7812.5000000000000000 | 8 20 | ANALYST | 4687.5000000000000000 | 1 20 | CLERK | 1484.3750000000000000 | 4 20 | MANAGER | 4648.4400000000000000 | 6 30 | CLERK | 1484.3800000000000000 | 2 30 | MANAGER | 4453.1300000000000000 | 5 30 | SALESMAN | 2187.5025000000000000 | 9 (9 rows) edb=# \crosstabview deptno job "Average Salary" ord deptno | ANALYST | CLERK | MANAGER | PRESIDENT | SALESMAN --------+-----------------------+-----------------------+-----------------------+-----------------------+----------------------- 10 | | 2031.2500000000000000 | 3828.1300000000000000 | 7812.5000000000000000 | 20 | 4687.5000000000000000 | 1484.3750000000000000 | 4648.4400000000000000 | | 30 | | 1484.3800000000000000 | 4453.1300000000000000 | | 2187.5025000000000000 (3 rows)
以上便把 PGSQL 樞紐表功能做了一輪範例了。如果在 Postgres 要有像試算表軟體的樞紐表一樣,要多出 Sum Total 這樣的欄位小計,就需要自己多加幾條查詢條件,然後用 crosstab() 呈現(\crosstabview 則不行),詳細用法可以看參考資料的連結。
從上面的操作看起來,試算表軟體(像是 M$ Office Excel 或是 Libreoffice Calc)的拖拉操作,對於熟悉的人來說,比起寫 SQL 指令還容易多了。不過由於這類軟體也不見得能裝這麼大筆的資料。
不過用所謂的 BI 工具好像就有提供類似的樞紐分析表圖形界面操作,而且資料源可以是資料庫查詢的資料結果~例如 Knime(KNIME | Pivoting in Databases)或是 Pentaho(範例請看 Applying Pivot in Pentaho Kettle - Stack Overflow)等等
順帶一提,在 Postgres 裡面,會被使用來當樞紐表欄位且品項內容固定的表格欄位,可以考慮選用 enum 型態,比較容易管理資料內容,排除這些欄位中資料發生內容筆誤的可能。
在上面的測試過程中,發現比較新版本的 psql 程式,就算連線到舊版資料庫(在這裡用 9.6 版 psql 連線到 PGSQL 9.2 資料庫),這個 \crosstabview Meta-Command 也是可以用的!
最後,透過內建樞紐表功能可以作一個無聊的小事:用 SQL 和樞紐表功能寫九九乘法表~用這個當作結束
edb=# select a, b
, a*b as "AxB"
from generate_series(1,9) a
cross join generate_series(1,9) b;
a | b | AxB
---+---+-----
1 | 1 | 1
1 | 2 | 2
1 | 3 | 3
1 | 4 | 4
1 | 5 | 5
1 | 6 | 6
1 | 7 | 7
1 | 8 | 8
1 | 9 | 9
2 | 1 | 2
2 | 2 | 4
2 | 3 | 6
2 | 4 | 8
2 | 5 | 10
2 | 6 | 12
2 | 7 | 14
2 | 8 | 16
2 | 9 | 18
3 | 1 | 3
3 | 2 | 6
3 | 3 | 9
3 | 4 | 12
3 | 5 | 15
3 | 6 | 18
3 | 7 | 21
3 | 8 | 24
3 | 9 | 27
4 | 1 | 4
4 | 2 | 8
4 | 3 | 12
4 | 4 | 16
4 | 5 | 20
4 | 6 | 24
4 | 7 | 28
4 | 8 | 32
4 | 9 | 36
5 | 1 | 5
5 | 2 | 10
5 | 3 | 15
5 | 4 | 20
5 | 5 | 25
5 | 6 | 30
5 | 7 | 35
5 | 8 | 40
5 | 9 | 45
6 | 1 | 6
6 | 2 | 12
6 | 3 | 18
6 | 4 | 24
6 | 5 | 30
6 | 6 | 36
6 | 7 | 42
6 | 8 | 48
6 | 9 | 54
7 | 1 | 7
7 | 2 | 14
7 | 3 | 21
7 | 4 | 28
7 | 5 | 35
7 | 6 | 42
7 | 7 | 49
7 | 8 | 56
7 | 9 | 63
8 | 1 | 8
8 | 2 | 16
8 | 3 | 24
8 | 4 | 32
8 | 5 | 40
8 | 6 | 48
8 | 7 | 56
8 | 8 | 64
8 | 9 | 72
9 | 1 | 9
9 | 2 | 18
9 | 3 | 27
9 | 4 | 36
9 | 5 | 45
9 | 6 | 54
9 | 7 | 63
9 | 8 | 72
9 | 9 | 81
(81 rows)
edb=# \crosstabview a b "AxB"
a | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
---+---+----+----+----+----+----+----+----+----
1 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
2 | 2 | 4 | 6 | 8 | 10 | 12 | 14 | 16 | 18
3 | 3 | 6 | 9 | 12 | 15 | 18 | 21 | 24 | 27
4 | 4 | 8 | 12 | 16 | 20 | 24 | 28 | 32 | 36
5 | 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 | 45
6 | 6 | 12 | 18 | 24 | 30 | 36 | 42 | 48 | 54
7 | 7 | 14 | 21 | 28 | 35 | 42 | 49 | 56 | 63
8 | 8 | 16 | 24 | 32 | 40 | 48 | 56 | 64 | 72
9 | 9 | 18 | 27 | 36 | 45 | 54 | 63 | 72 | 81
(9 rows)
參考資料:
沒有留言:
張貼留言